The CIA Triad and how I approached this
So, I had a thought. It would probably look bad if the guy with a website about cybersecurity had his website / account hacked into and altered without him knowing. Not to mention this site is under my name, so there’s that extra level of me wanting to ensure it retains its integrity.
All that being said, I decided, hey - why not look at this from the perspective of the CIA triad? And that thought lead to me writing a couple of scripts and then documenting it here. So, let’s begin in order and delve into how I thought to look a this from a security standpoint.
Confidentiality
Simply put, this step is irrelevant due to the fact that this is a static site I am hosting through a public repository - i.e. there is no personal or sensitive data to conceal. This site does not support any users creating accounts or anything else like that I might be worried about, so the confidentiality aspect of this is basically irrelevant. To protect any visitors coming to this site the best I can do is enforce secure protocols like HTTPS over HTTP. The integrity part is where I was mainly concerned, and that is where this gets more complicated.
Integrity
As I started off at the beginning of this page, I was mainly worried about the integrity aspect of the site, after all it is connected to some of my professional accounts like LinkedIn. There is also too much content for me to manually review - it would be far too time consuming and impractical.
So, I decided to automate this with a script (several actually), and since I’ve already got a raspbbery pi running a file sharing service back home, why not add this on there as a cronjob to run every hour or every day? I ended up breaking this into two separate scripts - the first to compare and hash the files against known good copies, and the second to send me an alert via email if any anomalies are detected.
1st Script - compare and hash files against known good hashes
EDIT: Parts of this script have been modified, so below may be a bit outdated.
For this part I’ll be highlighting the important parts while ignoring the rest of the steps like importing random modules. For the script in its entirety, click here.
First, I needed to get the zipped file off the repository, save it locally, and then unzip the file:
url="https://github.com/fe-moldark/wesleykent-website/archive/refs/heads/gh-pages.zip"
filetowrite=open(thezip,"wb")
filetowrite.write(requests.get(url).content)
filetowrite.close()
#try to unzip
try:
with zipfile.ZipFile(thezip) as z:
z.extractall("/media/pi/MyExternalDrive/save_wk_website/") #extracting to this folder
print "Succesfully unzipped the file."
except:
print "Invalid file type to unzip / failed to unzip."
sys.exit()
Now, this particular script is run once a day and checks the images stored on the site to ensure they haven’t been tampered with in any way. I’ve since changed this to simply collect and check every file downloaded (because why not), but if you wanted to keep it to just the images, then this way works too. So, from the location where I just saved the unzipped folder I need to get all those (image) path locations and save them to full_list:
main="/media/pi/MyExternalDrive/save_wk_website/wesleykent-website-gh-pages/assets/"
full_list=[]
for path, subdirs, files in os.walk(main):
for name in files:
location=os.path.join(path, name)
if str(location)[-4:] in [".png",".jpg"]: #this is not how I actually check for images, the example here just checks a list with common formats
full_list.append(location)
Now that I have all the paths for image files to check against, I compared them against known good files I have saved locally on the pi. To compare them, I took an MD5 hash of each and recorded any instances of different hashes to the badhashes list:
badhashes=[]
for item in full_list:
#compare hash from saved location below
tohash1=str(item)
#good copy for hash here
tohash2=str(item).replace("wesleykent-website-gh-pages","good_copy_wk_site")
#hash stuff now
hasher=hashlib.md5()
with open(tohash1, 'rb') as test_new:
buf=test_new.read()
hasher.update(buf)
NEW_HASH=hasher.hexdigest()
#needs 'try' since file might not exist
try:
hasher=hashlib.md5()
with open(tohash2, 'rb') as test_good:
buf=test_good.read()
hasher.update(buf)
GOOD_HASH=hasher.hexdigest()
except IOError:
GOOD_HASH="anewfilehasbeenloaded" #indicates an image formerly not on the site is now present
print NEW_HASH==GOOD_HASH, tohash1
print "+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++"
if NEW_HASH!=GOOD_HASH:
badhashes.append([str(tohash1).replace("/media/pi/MyExternalDrive/save_wk_website/wesleykent-website-gh-pages",""),NEW_HASH,GOOD_HASH])
Now that I have recorded those instances, let’s save them to the mail_body text file:
#begin mail_body
message=""
print "END of hashing ===============================\n"
print "Number of bad hashes: ", len(badhashes)
for item in badhashes:
print "Item "+str(badhashes.index(item))+": "+str(item[0])
#document notes to message variable
message+="\n"+"Total number of changes: "+str(len(badhashes))+"\n"
for item in badhashes:
if item[2]!="anewfilehasbeenloaded":
message+="\n"+"Changed image at: "+str(item[0])
message+="\n"+"Last known good hash: "+str(item[2])
message+="\n"+"Current hash: "+str(item[1])
else:
message+="\n"+"A suspected new image has been added at: "+str(item[0])+"\n"
#now write completed message to mail_body.txt file
now_save=open("/media/pi/MyExternalDrive/save_wk_website/mail_body.txt","w")
now_save.write(message)
now_save.close()
There’s a better way to do this, but the send_message_query text file records whether or not the email will actually be sent or not by the second script:
#there was a better way to do this next part, and no, I don't want to hear about it...
if len(badhashes)==0:
query=['False']
else:
query=['True']
yesno=open("/media/pi/MyExternalDrive/save_wk_website/send_message_query.txt","w")
yesno.writelines(query)
yesno.close()
At the end of all this, the script (which runs once a day as a reminder) runs a cleanup function to delete any old saves and the zip file:
#base path
base="/media/pi/MyExternalDrive/save_wk_website/"
theList=os.listdir(base)
#permanentlist are folders NOT to delete
permanentlist=["good_copy_wk_site","wesleykent-website-gh-pages",str(dateToday)[:-1]]
print permanentlist
for files in theList:
if os.path.isdir(os.path.join(base, files)):
if str(files) not in permanentlist:
shutil.rmtree(os.path.join(base, files))
That is all for the first script, on to the second.
2nd Script - deciding whether or not to send an alert, and if needed, sending it via SMTP
The link to the full second script can be found here. This first part below will define several variables, including the login credentials for the sending account and the email address of the recieving account:
#set variables that will be needed to send an email
ctx = ssl.create_default_context()
password = "sorry, not stupid enough to give you my password" #Your app password goes here
sender = "my_source_email@gmail.com" # Your e-mail address
receiver = "recieving_email@gmail.com" # Recipient's address
message = """\
From: "Alert" <my_source_email@gmail.com>
To: "Wesley Kent" <recieving_email@gmail.com>
Subject: Alert - images changed on wesleykent domain
Changes detected for wesleykent.com:
"""
Here, I open the two files that were created by the first script:
#open what was saved in the previous script - a log of all "bad" hashes and their locations
now_save=open("/media/pi/MyExternalDrive/save_wk_website/mail_body.txt","r")
all_lines=now_save.readlines()
now_save.close()
#again, better way to have saved this setting, but it works
yesno=open("/media/pi/MyExternalDrive/save_wk_website/send_message_query.txt","r")
result=yesno.readlines()[0]
yesno.close()
And check the result, if the alert status is True, aka not False, it will send an email using the saved credentials:
#If false, no email needed since no new alerts
if result=="False":
pass
else:
all_lines.pop(0)
#this is the mail_body.txt file here
for line in all_lines:
message+=str(line)+"\n"
#this sends the actual email
with smtplib.SMTP_SSL("smtp.gmail.com", port=465, context=ctx) as server:
server.login(sender, password)
server.sendmail(sender, receiver, message)
And just like that, an email is sent. Here is an example of what that alert looks like upon arrival:
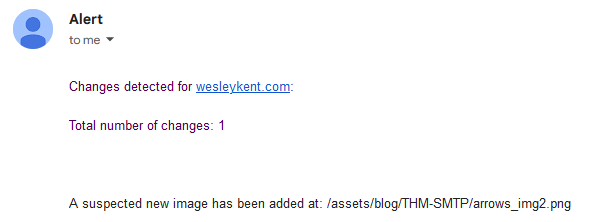
One last note before moving on, since I first wrote these scripts I have also added in another error exception in the event of no internet connection. I noticed once that it failed because of this and crashed not only this script but also an entirely separate python script I have that controls the LCD.
Now to implement these scripts as cronjobs
To get these scripts to run properly the files need to be modified as executable with chmod +x script_name.py, and sed -i -e 's/\r$//' script_name.py to work with their respective interpreters. Also - it is important that the files contain the proper “shebang” at the start of each script - for the downloadzip.py file, that was written in v2.7 so the shebang appears as #! /usr/bin/python2.7, and for the gmailzip.py file it appears as #! /usr/bin/python3.9.
Note: v2.7 is no longer the default python version for most distributions, so you will likely need to install that separately. I needed v2.7 specifically for the writelines() part when dealing with saving the files as wb - not sure what exactly is different between these versions here, I just rolled with it.
On the crontab, these jobs appear as:
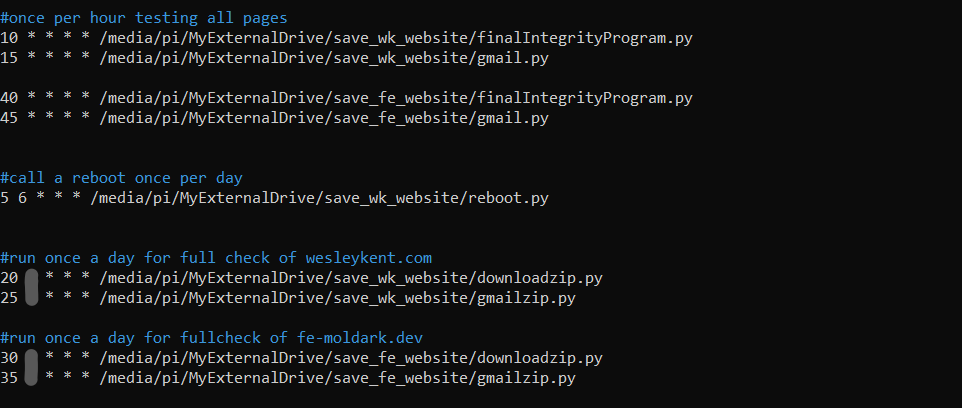
*I blurred out at what hour the full backups are done at, but you get the idea.
Those first four cronjobs are running hourly checks against known web pages only (i.e. excluding the images) and the fifth cronjob is a reboot I call once a day. The last 4 jobs are downloading the entire zipped repository and checking whether or not to send an email for both my websites, which is the example I just covered on this page. I did consider using a more dynamic script and using flags for each scenario, however I wanted clearer and more direct control of how each website was handled.
Circling back to the “integrity” idea, another action I can quickly take is to separate this GitHub hosted site from my actual wesleykent.com domain. This can be done by removing the CNAME records from either the GitHub repository or through my domain provider. Both scenarios would work and simply display something along the lines of “This domain is registerd under xyz domain provider” or a “404 - there isn’t a GitHub Pages site here”. This obviously takes away from the availability of the sites, but until I can correct them there is always the option to (temporarily) take it offline.
Availability
In terms of availability, I believe I am relatively well set. I periodicially create several full backups of both my sites in the highly unlikely event all of GitHub’s servers simultaneously fail, or if I want to move my website to another account, etc. Getting a site up and running under a new account and repository would take probably under 30 minutes. For a business environment that would not be ideal, but for a personal site like mine that is more than okay. I did consider having an entirely separate account with a full backup ready to go, and then making incremental / differential backups of the active site but that seemed way over the top.
The one thing I really can’t control are the Github Pages servers that are hosting the site. I think it’s safe to assume they won’t be out of commission very long if something does happen. As it stands now, I’m happy with the availability aspect of my sites.
Conclusion
Well, if you’ve made it this far, I applaud you. Unfortunately, as I was about to push this page to my main site I had one of those “Hold up, wait a minute, something ain’t right” moments. And that was a good humbling moment when I realized I wasn’t as clever as I thought I was, and I almost made a rather large error.
What I realized was this - I had just pushed an entire script to the web, with detailed notes on how it worked, and said “this is what I am running out of my home network.” At face value, the script is good - it alerts me to any changes that are made to my site without my knowledge. The way it learns whether or not to alert me is the issue. The scenario I presented was an individual somehow gained access to my account and had modified images, pages, etc - implying they can change the entirety of the repository as well. By detailing how I would routinely download the zip file and extract its contents I opened myself up to the possibilty for someone to turn the entire repository into a Zip Bomb that I would download, maybe some malicious exectuables could run, etc. Basically I had taken the threat to my website, and by trying to safeguard it, I had widened the attack surface to include my own LAN. Far from ideal.
So, how can I make sure the zip file is safe to unpack and examine? Well, the one guaranteed safe solution is to take a hash of the zipped file as a whole and compare just those. That will tell me if any changes had occured but offer no further insight, and that’s counterintuitive to the scripts I wrote.
Again, this threat with unpacking the zip file is a very specific concern. It assumes that a) someone obtained / cracked my password (a variation of which would supposedly take over 10 million years to brute force), and b) that someone would have the know-how to create and upload a malicious script to the repository that once unpacked, could cause damage either through loss of data or used to further exploit my network. That’s a lot of assumptions. Ultimately, to safeguard against this I now perform a number of checks against the zipped file first before extracting its contents for review. And yes, that is meant to sound as vague as humanly possible. Any details about that process would allow for a specific flaw in my reasoning to be found, so I’m going to keep it vague.
End of the day, I found all this a bit ironic knowing that one of the CTF exploits I ran through actually used a similar concept that manipulated a cronjob to escalate privileges. Did I way overthink this? Absolutely. Was it enjoyable? Also yes. I suppose when securing systems it’s better to be overly prepared than otherwise. Cheers.